A tutorial on exploratory factor analysis with SPSS
For this posting, I will be walking you through an example of exploratory factor analysis (EFA) using SPSS. A major focus in this discussion are the steps one typically considers when performing EFA and how to make decisions at various stages in the process.
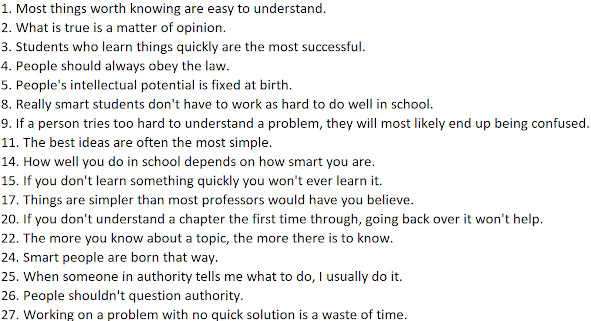
We will be factor analyzing items from the Epistemic Belief Inventory (EBI; Schraw et al., 2002) based on data collected from Chilean high school students in this study. Download a copy of the SPSS file containing the data here. The items for our analyses all have the root name 'ce' (see screenshot below). Although the original authors of the study analyzed all 28 items, to keep our output simpler, we will only perform the analysis on the 17 items contained in Table 2.

These items correspond to the following variables in the SPSS data file: ce1, ce2, ce3, ce4, ce5, ce8, ce9, ce11, ce14, ce15, ce17, ce20, ce22, ce24-ce27.

Video walkthrough of the analyses provided below:
The analyses
Step 1: Assess factorability of correlation matrix
[For this step, we will assume you have already examined the distributions of your variables and considered factors that may have impacted the quality of the correlations being submitted to factor analysis.]
The first question you need to ask yourself during EFA is whether you have the kind of data that would support factor analytic investigation and yield reliable results. Some issues can produce a factor solution that is not particularly trustworthy or reliable (Cerny & Kaiser, 1977; Dziuban & Shirkey, 1974), whereas others can result in algorithmic problems that may prevent a solution from even being generated (Watkins, 2018). The way to address this question is to evaluate the correlation matrix based on the set of measured variables being submitted to factor analysis. [In the current example, the measured variables are the items from the EBI. Hereafter, I will be referring to "items" throughout the discussion.] Answering the question of whether it is appropriate to conduct factor analysis in the first place can assist you in correcting problems before they emerge during analysis or (at the very least) serve as valuable information that can assist you in diagnosing problems that occur when running your EFA.
Generating output in SPSS for assessing factorability


A common preliminary step is to examine the correlation matrix based on your items for the presence of correlations that exceed .30 (in absolute value; Watkins, 2022). During factor analysis, the idea is to extract latent variables (factors) to account for (or explain) the correlational structure among a set of measured variables. If the items in your correlation matrix are generally trivial (i.e., very small) or near zero, this logically precludes investigation of common factors since there is little common variation among the variables that will be shared. Additionally, when screening your correlation matrix, you should also look for very high correlations (e.g., r's > .90) among items that might suggest the presence of linear (or near-linear) dependencies among your variables. The presence of multicollinearity among your variables can produce unstable results, whereas singularity in your correlation matrix will generally result in the termination of the analysis (with a message indicating your matrix is nonpositive definite). In the presence of singularity, certain matrix operations cannot be performed (Watkins, 2021). [Note: A common reason why singularity occurs is when an analyst attempts to factor analyze correlations involving a set of items along with a full scale score that is based on the sum or average of those items.]

The matrix is symmetric with 1's on the principal diagonal. If you wish to count the number of unique correlations greater than .30 (in absolute value), simply count the number in either the lower OR upper triangle. Counting the number of correlations in the lower triangle of this matrix, there look to be about 10 correlations [out of the p(p-1)/2 = 17(16)/2 = 176 unique correlations; remember, the matrix is symmetric about the principal diagonal containing 1’s] that exceed .30. None of the correlations exceed .90, which indicates to me low likelihood of any linear dependencies.
Investigate determinant of correlation matrix
The determinant of a correlation matrix can be thought of as a generalized variance. If this value is 0, your matrix is singular (which would preclude matrix inversion). If the determinant is greater than .00001, then you have a matrix that should be factorable. In our results, the determinant is .113, which is greater than .00001. You will find the determinant in your output at the bottom of the correlation matrix we just investigated.

This test is used to test whether your correlation matrix differs significantly from an identity matrix [a matrix containing 1’s on the diagonal and 0’s in the off-diagonal elements]. In a correlation matrix, if all off-diagonal elements are zero, this signifies your variables are completely orthogonal. Failure to reject the null when performing this test is an indication that your correlation matrix is factorable. In our output, Bartlett’s test is statistically significant (p<.001). [Keep in mind that Bartlett's test is often significant, even with matrices that have more trivial correlations, as the power of the test is influenced by sample size. Factor analysis is generally performed using large samples.]

The KMO MSA is another index to assess whether it makes sense to conduct EFA on a set of measured variables. Values closer to 1 on the overall MSA indicate greater possibility of the presence of common factors (making it more reasonable to perform EFA).

Here, we see the overall MSA is .78, which falls into Kaiser and Rice’s (1974) “middling” (but factorable) range [see scale below; Kaiser had a way with words didn't he???]


Step 2: Determination of number of factors
Once you have concluded (from Step 1) that it is appropriate to conduct EFA, the next step is to estimate the number of factors that may account for the interrelationships among your items. Historically, analysts have leaned on the Kaiser criterion (i.e., eigenvalue cutoff rule) to the exclusion of better options. This largely seems to be the result of this criterion being programmed into many statistical packages as a default. Nevertheless, this rule often leads to over-factoring and is strongly discouraged as a sole basis for determining number of factors.
Ideally, you will try to answer the 'number of factors question' using multiple investigative approaches. This view is endorsed by Fabrigar and Wegener (2012) who stated, “determining the appropriate number of common factors is a decision that is best addressed in a holistic fashion by considering the configuration of evidence presented by several of the better performing procedures” (p. 55). It is important to recognize, however, that different analytic approaches can suggest different possible models (i.e., models that vary in the number of factors) that may be explain your data. Resist the temptation to run from this ambiguity by selecting one and relying solely on it (unless perhaps it is a method that has a strong empirical track record for correctly identifying factors; a good example is parallel analysis). Instead, consider the different factor models[or at least a reasonable subset of them] as 'candidates' for further investigation. From there, perform EFA on each model, rotate the factors, and interpret them. The degree of factor saturation and interpretability of those factors can then be used as a basis for deciding which of the candidate models may best explain your data.
See this posting for discussion of consequences of over- and under-factoring.
Methods 1 & 2: Parallel analysis and MAP test
Parallel analysis is a method that has strong empirical support as a basis for determining the number of factors. This method involves simulating a large number of correlation matrices (assuming the same number of variables and sample size as the original data) and then computing the average or the 95th percentile of the eigenvalues from those randomly generated matrices. These randomly generated eigenvalues are compared against the eigenvalues from the raw data. You maintain the number of factors that contain eigenvalues from your raw data that exceed those generated at random (using either the mean or 95th percentile of the eigenvalues).
The MAP test involves comparing PCA models that vary in the number of extracted components with respect to sums of squared partial correlations. The starting point for the method is to extract 0 components and simply compute the average of the squared zero-order correlations among a set of variables. Next, a single component (i.e., 1 component model) is extracted and the average of the squared partial correlations (i.e., after partialling the first component) is computed. Following, two components are extracted (i.e., 2 component model) and the average of the squared partial correlations (i.e., after partialling the first two components) is computed; and so on. The number of recommended factors based on this procedure is associated with the component model that has the smallest average (partial) correlations.
I have created a new syntax file based on O'Connor's syntax for conducting parallel analysis and the MAP test, whereby both functions are integrated into a single file. Download here. To perform the analysis, simply open up the raw data file and the syntax file. [My strong suggestion is to avoid having multiple other files open.]


Scroll to the bottom of the file and then add the variable names in line 183.
Following, right click and select Run All. This should generate your output for both parallel analysis and the MAP test.


Next, we see the output for the MAP test. Interestingly, the smallest squared partial correlation was associated with a one-factor model. As such, the analysis suggests a one-factor model may be tenable.

The scree test is one of the older methods for identifying number of factors. This test involves plotting the eigenvalues (Y axis) against factor number (X axis). In general, the plot of the eigenvalues look like the side of a mountain with the base of the mountain containing 'rubble'. To obtain the scree plot go under the Extraction tab and select 'Scree plot'. [The default Kaiser criterion is also in place as well.]



Method 4: Kaiser criterion/eigenvalue cutoff rule
The Kaiser criterion (aka, eigenvalue cutoff rule) states that the number of factors to retain during factor analysis is equivalent to the number having an eigenvalue greater than 1. This criterion should only be applied following extraction of the principal components from an unreduced correlation matrix. The idea behind the Kaiser criterion is that you should only retain those factors that account for at least as much variation as at least one measured variable (see Kaiser, 1960). A major criticism of use of this criterion is that it has tendency to result in overfactoring. The Kaiser criterion is the default approach to identifying the number of factors in SPSS.

In the table below, the first column (Total) under Initial Eigenvalues contains eigenvalues from the principal components extraction [these are also the same eigenvalues that are plotted against component number in our scree plot above]. As you can see, the eigenvalues appear in descending order, with each subsequent component explaining less and less of the total variation in the original set of measured variables (items). The first three of the eigenvalues in the table exceed 1. With the default (Kaiser criterion) in place, the program then decided to retain these three components [see the eigenvalues under Extraction Sums of Squared Loadings]. The reason the eigenvalues for these factors is the same as the original is that the default extraction method is Principal components analysis (which is another problem, since PCA is not based on the common factor analytic model).

If you select an alternative extraction approach (such as Principal axis factoring, or PAF) without changing the default, it will remain in place and continue to force the program to select the number of factors that meet the Kaiser criterion - irrespective of any number you decide upon using other means of investigation such as the scree plot, the MAP test, parallel analysis, etc. Below is an example of the default in place, even after selecting PAF.


The only way to overcome this problem is to decide on the number of factors (based on those other tests) and then force a factor solution with your preferred extraction approach. [It just so happens that the Kaiser criterion suggested the same number of factors we identified using a couple of other approaches - e.g., parallel analysis and scree test. However, the suggested number of factors can differ between approaches. As such, you may ultimately need to examine several models differing in the number of factors to decide which is the best way to represent the data. That would require using this option as well.]

*******************************************************
Step 3: Final extraction of factors, rotation, and interpretation
At this point, I have determined the most likely candidate is a model containing three factors [The one-factor model suggested by the MAP test is unlikely, especially given evidence epistemic beliefs are multidimensional]. For this reason, the remainder of this discussion will be based on a three-factor model. To perform the analysis, we will rely on Principal Axis Factoring (PAF) for factor extraction. Watkins (2018) notes factor extraction involves transforming correlations to factor space in a manner that is computationally, but not necessarily conceptually, convenient. As such, extracted factors are generally rotated to "achieve a simpler and theoretically more meaningful solution" (p. 231). For our example, we will consider two factor rotation approaches (Promax and Varimax) to facilitate interpretation of the final set of factors that are extracted. Promax rotation is one type of oblique rotation that relaxes the constraint of orthogonality of factors, thereby allowing them to correlate. Varimax rotation is a type of orthogonal rotation. When Varimax rotation is used, the factors are not permitted to correlate following rotation of the factor axes.
PAF with Promax rotation
To perform the analysis using the dropdown windows, go under the Extraction tab and click 'Fixed number of factors to extract'. Provide the number of factors to extract (based on the steps taken above to determine the number of factors).


The output
The table below contains initial and extracted communalities. During principal axis factoring (PAF), the values in the first column (Initial) are placed into the principal diagonal of the correlation matrix (instead of 1's). It is this reduced correlation matrix that is factored. The Initial communalities are computed as the squared multiple correlation between each measured variable (item) and the remaining variables (items). [You can easily generate these by performing a series of regressions where you regress each variable onto the remaining variables and obtaining the R-squares.] The Extraction communalities are final estimates of the proportion of variation in each item accounted for jointly by the set of common factors that have been extracted.



The next set of values [Rotated Sums of Squared Loadings] are eigenvalues following factor rotation. Since the factors are now allowed to correlate (recall, Promax is an oblique rotation), we cannot compute percentage of variance uniquely accounted for in the items due to the rotated factors.

The next set of output contains a Pattern matrix with unrotated factor loadings. The loadings are zero-order correlations between the items and the factors that have been extracted.

It is instructive to think about how these loadings are related to the eigenvalues and final communalities in the previous two tables. First, the communalities in the Extraction column (see below) can be computed as the sum of the squared loadings in the factor pattern matrix. For 'ce1', the communality is computed as: (.095)2+(.33)2+(.299)2 = .207. For 'ce5', the communality is computed as: (.524)2+(-.056)2+(-.029)2 = .278. Since the factors are extracted such they are orthogonal, the square of a particular loading indicates the proportion of variation uniquely accounted for by a factor. Moreover, summing across those squares provides an R-square type value (i.e., the communality) indicating the proportion of variation in an item accounted for by the set of factors.










Cerny, B. A., & Kaiser, H. F. (1977). A study of a measure of sampling adequacy for factor-analytic correlation matrices. Multivariate Behavioral Research, 12(1), 43–47.
Dziuban, C. D., & Shirkey, E. C. (1974). When is a correlation matrix appropriate for factor analysis? Psychological Bulletin, 31, 358-361.
Kaiser, H. F. (1960). The application of electronic computers to factor analysis. Educational and Psychological Measurement, 20, 141–151.
Leal-Soto, F., Ferrer-Urbina, R. (2017). Three-factor structure for Epistemic Belief Inventory: A cross-validation study. PLoS ONE, 12 (3): e0173295. doi:10.1371/journal.pone.0173295
Pituch, K.A., & Stevens, J.P. (2016). Applied multivariate statistics for the social sciences (6th ed.). New York: Routledge.
Schraw, G., Bendixen, L. D.,
& Dunkle, M. E. (2002). Development and validation of the Epistemic Belief
Inventory (EBI). In B. K. Hofer & P. R. Pintrich (Eds.), Personal epistemology:
The psychology of beliefs about knowledge and knowing (pp. 261–275). Lawrence Erlbaum Associates Publishers.
Watkins, M. W. (2018). Exploratory factor analysis: A guide to best practice. Journal of Black Psychology, 44, 219-246.
Watkins, M. W. (2021). A step-by-step guide to exploratory factor analysis with R and RStudio. New York: Routledge.


Comments
Post a Comment